Programación asistida por IA: qué funcionó para mí y qué no (después de 6 meses)

1. Introducción
Durante los últimos seis meses, la programación asistida por IA se ha convertido en una parte fundamental de cómo construyo software.
La he usado casi a diario en mis proyectos sobre AWS. Uno de ellos es mi proyecto personal https://playingpadel.es, una web para jugadores de pádel que sigue evolucionando.
En este tiempo he probado distintas herramientas (Amazon Kiro, Copilot, Antigravity, Cursor, Windsurf). Todas me ayudaron a iterar más rápido. Y en todas, en algún momento, acabé cometiendo errores por las mismas razones.
Ahí fue cuando me di cuenta de algo importante: importaba mucho menos la herramienta y mucho más cómo la usaba. Los mismos errores aparecían en todas cuando me saltaba la validación o les daba demasiada libertad.
Para algo sencillo, o incluso para una prueba de concepto (PoC), puedes usar estos asistentes de muchas formas y casi todo parece funcionar. Pero cuando los aplicas sobre código productivo, la historia cambia.
Necesitas más disciplina y más control: alcance acotado, límites claros, tests y verificación. Si no, la velocidad se vuelve engañosa: avanzas rápido hoy, pero lo pagas después en deuda técnica, regresiones y sorpresas en producción.
Este artículo no va de hype ni de herramientas. Es un resumen práctico de lo que no me ha funcionado, de lo que sí, y del flujo de trabajo que me ha mantenido a salvo mientras construía y evolucionaba mis sistemas.
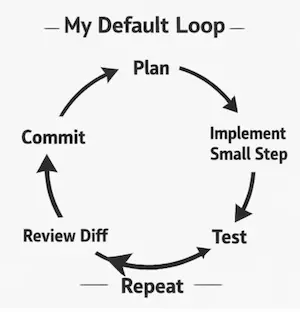
2. Mi bucle de trabajo por defecto
Antes de entrar en lo que no funcionó, este es el bucle que intento seguir cada día cuando estoy escribiendo código con ayuda de IA:
- Planificar un pequeño cambio
- Implementar
- Probar
- Revisar los cambios
- Hacer commit
- Repetir
3. Mapeo: de mis errores a mis soluciones
Esto es un resumen rápido para orientarte. El valor está en los detalles: ejemplos, matices y cómo se conectan entre sí.
| Qué no funcionó (sección 4) | Qué funcionó (sección 5) |
|---|---|
| Pedir demasiadas cosas a la vez | Mantener cambios pequeños y acotados (5.1) |
| Confiar ciegamente en el código generado | Revisar el plan y los cambios antes de implementar (5.2) |
| No pedir validación explícita | Pedir verificación, no solo código (5.5) |
| Perder el control del código | Refactorizar después de que funcione (5.7) |
| No poner restricciones claras | Definir intención y límites con detalle (5.3) |
| Elegir atajos sin pensar a largo plazo | Checklist y validación continua (5.8) |
| No hacer commits con frecuencia | Hacer commits pequeños y frecuentes (5.6) |
| Demasiados tests sin estrategia | Tratar los tests como contrato (5.4) |
| Usar modelos débiles para tareas complejas | Usar el modelo adecuado según el tipo de tarea (5.9) |
| Saltar entre herramientas constantemente | Dominar una herramienta y configurarla bien (5.9) |
4. Qué no funcionó para mí
Esta sección es larga a propósito, porque los fallos que cometí no fueron “uno o dos”. Fueron patrones que se repetían bajo distintas formas.
Lo importante es que muchos de estos problemas comparten la misma raíz: cuando rompes el bucle de control (revisión, validación y feedback), todo se degrada muy rápido.

4.1. Pedir demasiadas cosas a la vez
El error más común que cometí fue pedir a la IA que implementara demasiados cambios en una sola petición.
Incluso cuando el resultado es aparentemente correcto, los cambios se vuelven difíciles de revisar y la validación se ralentiza. Ahí es donde empiezan a colarse los bugs.
Qué aprendí
- La generación rápida solo ayuda si el bucle de validación también es rápido.
- Si no puedo validar algo con facilidad, no debería generarlo en bloque.
- Los cambios pequeños reducen estrés y errores.
4.2. Confiar ciegamente en el código generado
A veces el código se ve limpio y “bien hecho”. Eso no significa que sea correcto, seguro o coherente con tu sistema.
El problema es que muchos errores no son obvios. No rompen el build, no fallan en local, y aun así introducen cambios de comportamiento: validaciones que desaparecen, retries que se disparan, timeouts mal puestos o casos borde que quedan sin cubrir.
En cloud esto se nota aún más, porque esos cambios pueden acabar traduciéndose en latencia, costes inesperados o degradación bajo carga real.
Qué aprendí
- No asumir que “si compila, está bien”.
- No asumir que solo con pasar los test unitarios, “está bien”.
- Revisar el código generado como revisaría una PR de un compañero.
- Si no puedo explicar una parte del código, no la quiero en producción.
4.3. No pedirle a la IA que valide su propio trabajo
Muchos asistentes hacen cambios y se detienen. No validan nada a menos que se lo pidas explícitamente.
Si asumes que lo generado funciona, normalmente acabarás probándolo tú, fallará y perderás tiempo reconstruyendo contexto.
Qué aprendí
- Pedir siempre implementación más validación.
- “Implementar + validar con tests + explicar por qué funciona” es un buen patrón por defecto.
- La verificación no es una fase extra, es parte del trabajo.
4.4. Perder el control del código
Esto pasa más rápido de lo que parece. Empiezas a pedir cambios y llega un punto en el que ya no sabes exactamente qué tienes ni cómo funciona.
La IA puede generar código que funciona, pero tú sigues siendo el propietario y responsable de mantenerlo.
Qué aprendí
- Si algo no está claro, pedir explicaciones antes de seguir.
- Preferir código simple incluso si es un poco más largo.
- No avanzar hasta entender el estado actual del sistema.
4.5. No poner restricciones claras
Sin restricciones, el asistente tomará decisiones por ti: cambiará estructura, añadirá dependencias o “mejorará” cosas que no pediste.
El problema no es que lo haga, sino que lo hace sin contexto.
Qué aprendí
- Las restricciones no son opcionales.
- Ser explícito sobre lo que NO quiero evita sorpresas.
- Reglas como “diff mínimo”, “sin nuevos servicios” o “no tocar IAM” ahorran muchos problemas.
4.6. Elegir el camino rápido sin pensar en el largo plazo
Acepté atajos porque quería la solución rápidamente. Más tarde, revertirlos fue costoso y lento.
Lo que parecía una decisión pragmática acabó convirtiéndose en deuda difícil de pagar.
Qué aprendí
- Pensar en los tradeoffs antes de aceptar un atajo.
- Documentar cualquier decisión temporal con un plan de salida.
- Ser especialmente cuidadoso cuando el atajo afecta a seguridad, datos o costes.
4.7. No hacer commits con frecuencia
Acumular cambios que funcionan sin hacer commit es acumular riesgo.
Sin commits pierdes trazabilidad, puntos de rollback y confianza para seguir iterando.
Qué aprendí
- Los commits pequeños reducen el miedo.
- Los checkpoints hacen que experimentar sea más barato.
- Si algo sale mal, volver atrás debería ser sencillo.
4.8. Tener demasiados tests sin una estrategia clara
Hoy en día es muy fácil generar tests. También es muy fácil acabar con una suite lenta y redundante.
En mi proyecto de pádel, llegué a tener cientos de tests E2E, muchos de ellos repetidos, y no quería ejecutarlos porque tardaban mucho tiempo.
Qué aprendí
- Los tests necesitan una estrategia, no solo volumen.
- Los tests lentos son un coste diferido.
- No todos los cambios necesitan tests del mismo nivel.
4.9. Usar modelos más débiles para tareas complejas
Intenté “ahorrar tokens” usando modelos pequeños en tareas que no eran simples. El resultado fue más tiempo perdido corrigiendo y repitiendo.
Qué aprendí
- Si esta opción existe en tu asistente, deja que él elija que modelo utilizar. Suele ser la mejor opción, a no ser que sepas lo que haces.
- Si eliges, Usa el modelo adecuado para la complejidad del problema.
- Modelos pequeños para boilerplate.
- Modelos potentes para diseño, debugging y refactors con riesgo.
4.10. Saltar entre herramientas demasiado a menudo
Cambiar entre IDEs, chats y asistentes me hizo perder contexto y coherencia.
Cada herramienta tenía reglas y supuestos distintos.
Qué aprendí
- No cambiar de herramienta a mitad de una tarea.
- Si cambio de herramienta, copiar explícitamente plan y restricciones.
- Cerrar mi bucle de trabajo antes de pasar a otra cosa.
5. Qué funcionó para mí
Si la sección anterior recoge los errores, esta es la parte práctica: las prácticas que, en conjunto, me han permitido usar asistentes de código sin perder el control.
No son trucos ni atajos. Son hábitos repetibles que me ayudan a mantener el ritmo sin sacrificar calidad.
La mayoría de estas prácticas son aburridas.
Precisamente por eso funcionan.

5.1. Mantener el control: pedir un cambio, validar y continuar
Si tuviera que elegir un único cambio que hizo que todo lo demás fuera más fácil, sería este.
Antes pedía demasiadas cosas en una sola petición. Ahora voy de una en una: pido un cambio acotado, lo valido y continúo.
En lugar de pedir algo como “refactorizar todo el módulo”, pido una mejora concreta y pequeña.
Los cambios pequeños son más fáciles de revisar, la validación se mantiene rápida y los rollbacks dejan de dar miedo.
5.2. Revisar los cambios antes de implementarlos
Cuando el cambio es complejo, importante o con impacto, reviso primero qué se va a hacer antes de que se escriba código.
Mi patrón es simple:
- Primero pido el plan (opciones, riesgos y pasos).
- Cuando estoy conforme, pido que implemente solo lo acordado.
Así evito sorpresas y mantengo el control del alcance.
Trato al asistente como a un compañero de equipo. Si no puedo revisar los cambios rápido, el problema no es el asistente. Es el tamaño o la cantidad de los cambios.
Regla rápida: si los cambios son grandes, primero los divido. Prefiero tres cambios pequeños que uno enorme.
5.3. Definir lo que quiero, con el mayor detalle posible
Cuando el prompt es vago, la respuesta también lo es. Si no eres claro, el asistente rellenará los huecos por ti.
No sigo una plantilla rígida, pero casi siempre incluyo:
- qué quiero
- qué no quiero (límites claros)
- cómo sabré que está bien hecho (criterios de aceptación)
- contexto relevante para esta implementación
Esto puede parecer excesivo, pero reduce malentendidos y mejora mucho la calidad del resultado.
Amazon Kiro tiene un modo basado en especificaciones (spec-driven development) que obliga a definir la intención primero, validar cómo se va a construir y solo entonces generar código. Es incómodo al principio, pero reduce errores.
5.4. Tener una estrategia de tests clara
Los tests no están solo para “que pase el pipeline”. Están para darte control: confianza para cambiar cosas y detectar regresiones rápido.
Lo que me funciona es decidir tres cosas de forma explícita:
- Qué niveles de tests tengo (y cuál es su objetivo).
- Cuándo añado tests nuevos (por ejemplo: nueva funcionalidad, nuevo bug, nuevo caso borde).
- Cuándo los ejecuto (qué corre siempre en PR y qué reservo para momentos concretos).
Mis niveles, ordenados por criticidad, son:
- Nivel 1: Smoke tests
- Nivel 2: Unit tests
- Nivel 3: Integration tests
- Nivel 4: Contract / API tests
- Nivel 5: E2E tests
Ten cuidado con los tests E2E que generan efectos secundarios reales (emails, escrituras de datos, eventos de AWS, etc.). Si añades E2E, añade también limpieza y aislamiento.
Cuando un test generado falla, el asistente puede “arreglarlo” debilitando el propio test. Eso puede dejar el pipeline en verde mientras el bug sigue ahí.
Una línea de prompt que me ayuda:
1
2
No cambies los tests solo para que pasen. Revisa primero el código real.
Si cambias un test, explica por qué la expectativa original era incorrecta.
5.5. Pedir verificación, no solo código
Muchas veces pedí cambios y recibí código que, simplemente, no funcionaba.
La buena noticia es que esto suele tener una solución sencilla: pedir explícitamente verificación.
Por defecto, pido:
- que compruebe que el código funciona (tests relacionados)
- un plan de verificación corto
- tests para añadir o actualizar
Si algo falla, mi regla es simple: parar, revisar y volver a iterar añadiendo más contexto y si es necesario, reduciendo el alcance.
Cuando el cambio es delicado, añado una revisión rápida de riesgos (seguridad, fiabilidad, coste y mantenibilidad). En un minuto suelen aparecer problemas obvios.
5.6. Hacer commit frecuentemente
Los commits pequeños me dan seguridad.
Hago commit después de cada paso que funciona, antes de pedir cambios arriesgados y siempre que termino un refactor o mejoras de tests.
Si el asistente se va por un camino raro, volver atrás es trivial.
Sin commits frecuentes, la velocidad que ganas programando la pierdes en miedo a romper cosas.
5.7. Refactorizar con clean code, después de que funcione
La IA es muy buena reescribiendo código, pero yo primero quiero que funcione.
El flujo que me funciona es:
- Tener cambios correctos
- Automatizar comprobaciones
- Refactorizar con principios de clean code
Cuando la respuesta se ve caótica, lo pido explícitamente: “aplica principios de clean code” (funciones pequeñas, nombres significativos, responsabilidad única) y justifica cualquier refactor que propongas.
“Los principios de Clean Code buscan código legible, mantenible y eficiente, enfocándose en nombres claros y descriptivos, funciones pequeñas que hacen una sola cosa (SOLID principles), DRY (Don’t Repeat Yourself), reglas de formato consistentes, manejo de errores y tests unitarios. La Regla del Boy Scout (“deja el código más limpio de como lo encontraste”) es fundamental, junto con principios SOLID para diseño de clases y una buena gestión de dependencias.”
5.8. Checklist ligera al final del bucle
Antes de hacer merge (o incluso antes de parar por hoy), reviso esta lista:
- ¿Revisé los cambios?
- ¿Mi código compila?
- ¿Los tests cubren lo crítico?
- ¿Mis tests funcionan?
- ¿Mi código sigue las reglas de lint que tengo definidas?
- ¿Mantuve los cambios acotados?
- ¿Hice commit?
- ¿Verifiqué suposiciones?
Suena básico, pero previene la mayoría de los problemas de mañana.
5.9. Dominar una herramienta y configurarla bien
Elegir una herramienta principal y configurarla bien cambió completamente mi experiencia.
Cambiar de herramienta constantemente me hacía perder contexto y, sobre todo, mis reglas: estilo, límites y forma de pedir cambios.
Cuando dejé una herramienta bien configurada (reglas persistentes, plantillas, atajos), la calidad subió de golpe y la fricción bajó mucho: menos reexplicar contexto, menos repetir reglas y menos sorpresas.
Más adelante escribiré un post específico sobre Amazon Kiro y su modo SPEC, porque ahí esto se nota especialmente.
Si tu IDE soporta reglas persistentes (reglas de proyecto, instrucciones personalizadas o directrices de workspace), pon tus valores por defecto allí para que cada solicitud empiece desde la misma línea base.
5.10. Mantener la calma y tratar a la IA como una herramienta, no como un enemigo
Cuando algo no sale como espero, es muy fácil frustrarse y empezar a responder de forma impulsiva. Eso casi siempre empeora el resultado.
He aprendido que la calidad del resultado depende mucho de mi estado mental. Si estoy cansado, frustrado o con prisa, lo noto inmediatamente en la calidad de los prompts y en las respuestas.
Qué hago ahora
- Paro cuando noto frustración.
- Reformulo el prompt con calma y más contexto.
- Trato al asistente como una herramienta predecible, no como alguien que “me entiende”.
Puede parecer un detalle menor, pero rompe muchos bucles malos antes de que escalen.
6. Pensamientos finales

La programación asistida por IA cambia la velocidad de forma radical.
Pero la velocidad sin control solo amplifica los problemas existentes.
Cuando trabajas con sistemas reales, especialmente en cloud, un pequeño error puede convertirse rápidamente en un problema de fiabilidad, seguridad o coste.
Gran parte de lo que cuento aquí fue refinado mientras iteraba en mi proyecto personal https://playingpadel.es.
La lección más importante que me llevo después de estos meses es simple: la herramienta importa menos que el método.
Si tuviera que resumir todo el artículo en una sola idea sería esta: mantén el bucle sano. Cambios pequeños, validación constante y decisiones conscientes.
La IA no construye sistemas por ti.
Cambia la velocidad a la que los construyes.Sin método, amplifica el caos.
Con buen criterio, amplifica la ingeniería.